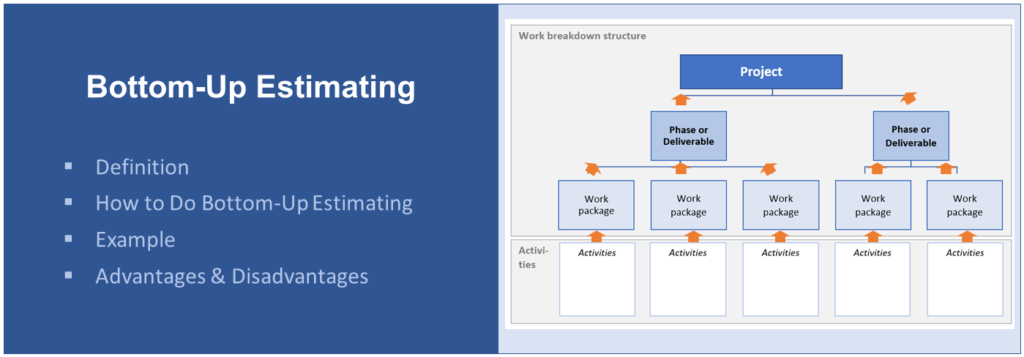
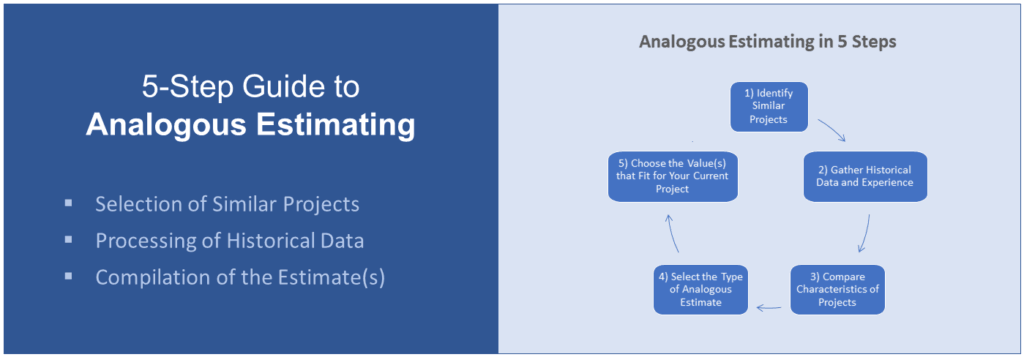
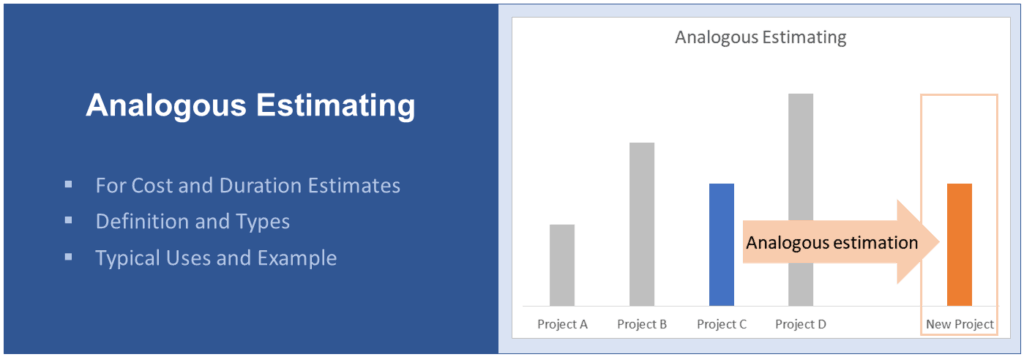
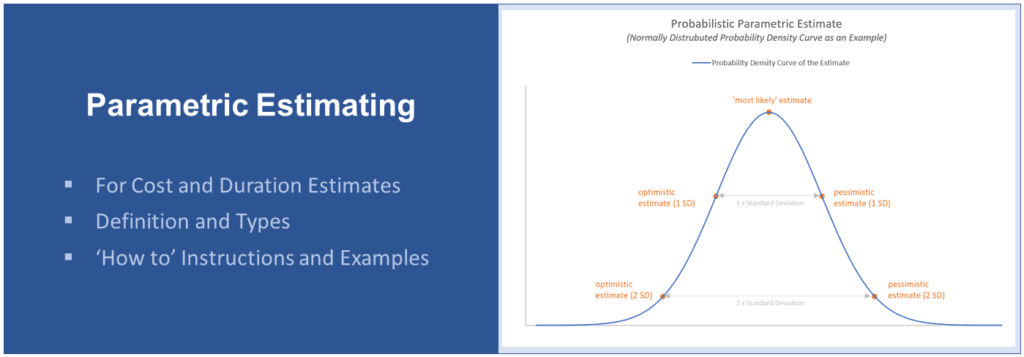
What Are Leads and Lags in Project Management?
‘Leads and Lags’ is a technique of several processes in the area of Project Schedule Management according to PMI’s Guide to the Project Management Body of Knowledge (PMBOK®, 6th ed., ch. 6.3.2). They refer to the potential advance or delay of activities within a project schedule and are essential when it comes to scheduling activities on …